Introduction to tries through Facebook Hacker Cup 2015 Round 1 - Autocomplete
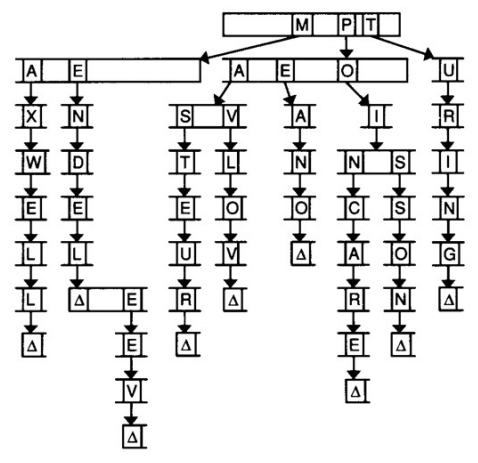
In the last week's post I discussed the solution to the problem "Homework" from Facebook Hacker Cup 2015 Round 1. This post is about the problem "Autocomplete" from the same round. You can read the problem statement available on the Facebook website. If you don't have a Facebook account, you can download problem statements from Codeforces Gym . I will re-state the problem in fewer lines. You have a new phone which has an auto-complete feature. But, it will complete your word only if there is there is no ambiguity on how the word should be completed. Formally, it will complete a word iff there is exactly one way to complete the word. It so happens that the phone's dictionary is empty by default. So, for the auto-complete feature to work, before typing a word you need to add that word to the dictionary. You need to send a message containing \(N\) words. What is the minimum number of characters must you type to send all \(N\) words? (Note that the ...